
Mengapa AI Memindahkan Komputasi Lebih Dekat ke Penyimpanan
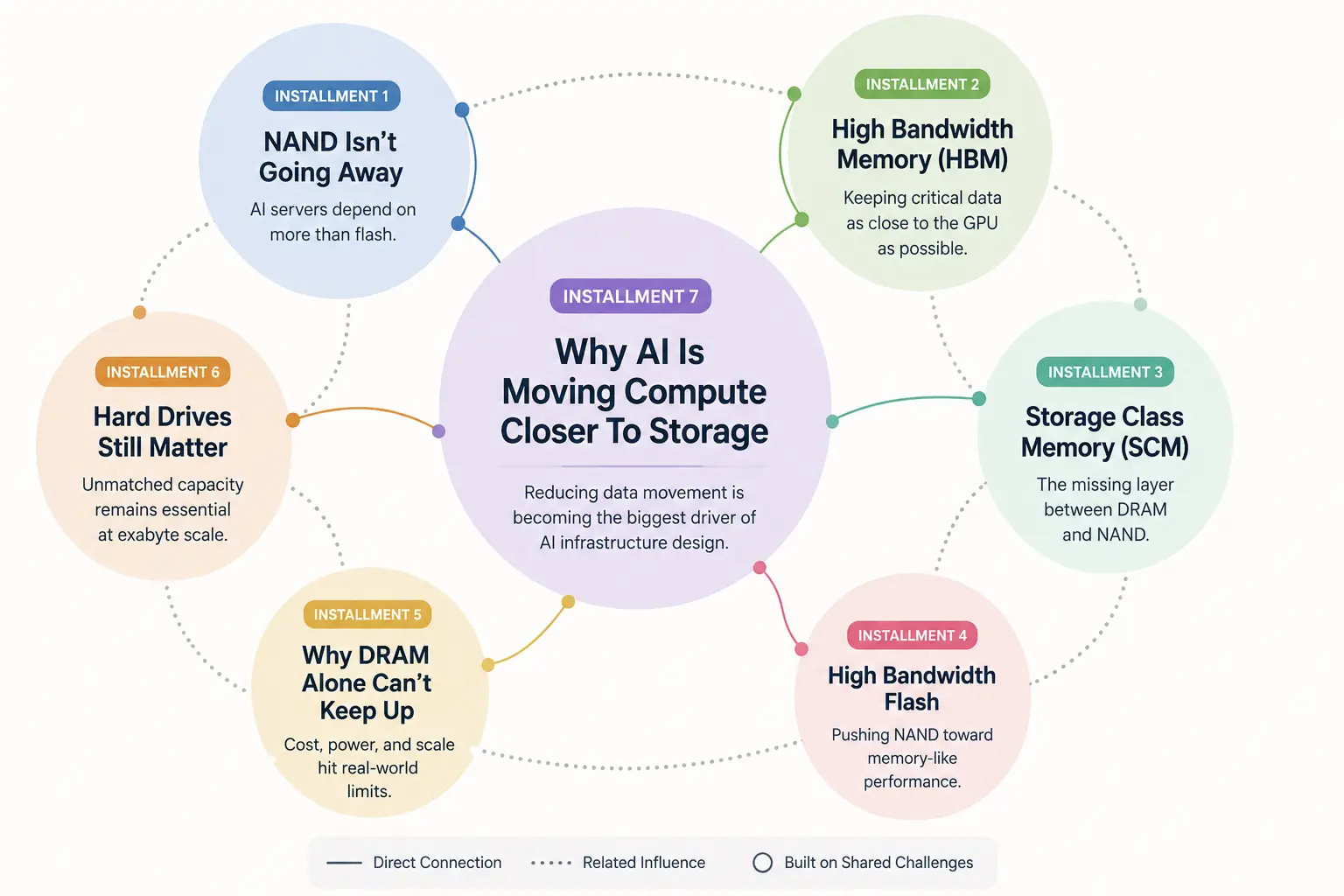
Jika Anda mengikuti bagian-bagian sebelumnya dalam seri ini, kemungkinan besar Anda mulai melihat sebuah pola yang muncul.
Dalam artikel pertama, kita membahas bagaimana flash NAND tidak sedang menghilang, melainkan menjadi bagian dari hierarki memori AI yang jauh lebih besar. Setelah itu, kita melihat High Bandwidth Memory (HBM) dan mengapa GPU modern bergantung pada data yang secara fisik berada lebih dekat ke prosesor. Lalu kita masuk ke Storage Class Memory, High Bandwidth Flash, keterbatasan penskalaan DRAM, dan akhirnya mengapa bahkan hard drive tradisional masih tetap penting, karena infrastruktur AI bekerja pada skala yang sering kali sangat diremehkan oleh banyak orang.
Sekilas, semua itu mungkin tampak seperti topik yang terpisah.
Sebenarnya tidak.
Semuanya adalah gejala dari tekanan mendasar yang sama: sistem AI tidak lagi terutama berjuang melawan kurangnya daya komputasi. Sistem AI sedang berjuang dengan seberapa efisien data dapat dipindahkan.
Perubahan itu mengubah hampir semua hal tentang bagaimana infrastruktur dirancang.
Selama puluhan tahun, komputasi mengikuti model yang cukup stabil. Penyimpanan menyimpan data, memori menyiapkannya, dan prosesor mengambil apa yang dibutuhkan. Ketika prosesor menjadi semakin cepat, sistem hanya mencoba memberi mereka data dengan lebih efisien menggunakan bus yang lebih baik, cache yang lebih besar, dan teknologi memori yang lebih cepat.
AI mengubah skala masalahnya.
Cluster GPU modern dapat memproses informasi dengan kecepatan yang begitu besar sehingga tindakan memindahkan data di dalam sistem mulai menjadi salah satu bottleneck terbesar dalam seluruh arsitektur. Dalam beberapa lingkungan, prosesor itu sendiri bukan lagi bagian yang lambat. Keterlambatan muncul karena data yang tepat harus sampai ke prosesor dengan cukup cepat dan cukup konsisten agar prosesor tetap digunakan secara penuh.
Kesadaran itu secara diam-diam mendorong industri ke arah baru.
Alih-alih terus-menerus memindahkan jumlah data yang semakin besar bolak-balik melintasi sistem, infrastruktur AI mulai memindahkan sebagian komputasi lebih dekat ke tempat data sudah berada.
Dan setelah Anda memahami mengapa hal itu terjadi, banyak artikel sebelumnya dalam seri ini mulai terasa jauh lebih jelas hubungannya.
AI Mulai Menabrak Dinding Perpindahan Data
Salah satu gagasan paling penting dari artikel HBM sebelumnya adalah bahwa sistem AI modern sering melambat bukan karena prosesor kekurangan kemampuan komputasi, tetapi karena sistem tidak dapat mengirimkan data dengan cukup cepat untuk membuat prosesor tetap sibuk.
Masalah itu menjadi jauh lebih serius ketika workload AI berkembang ke seluruh rack dan cluster.
Sebuah akselerator AI modern dapat mengonsumsi informasi dalam jumlah yang luar biasa secara paralel. Masalahnya adalah dataset tidak lagi cukup kecil untuk sepenuhnya berada di dalam lapisan memori tercepat. Bahkan dengan HBM dan pool DRAM yang besar, sejumlah besar data masih harus bergerak melalui interconnect, bus, fabric, lapisan penyimpanan, dan infrastruktur jaringan.
Pergerakan itu punya biaya.
Biaya itu muncul sebagai latensi, tetapi itu hanya sebagian dari ceritanya. Biaya itu juga muncul sebagai konsumsi daya, panas, kebutuhan pendinginan, kemacetan, keterlambatan sinkronisasi, dan siklus komputasi yang menganggur. Seperti yang kita bahas dalam bagian DRAM, bahkan jeda yang sangat kecil bisa menjadi sangat mahal ketika ribuan GPU bekerja pada saat yang sama. Jeda kecil yang dikalikan ke seluruh cluster AI besar dapat berarti hilangnya utilisasi dalam jumlah yang sangat besar.
Hal itu mengubah prioritas rekayasa.
Selama bertahun-tahun, infrastruktur sebagian besar dirancang untuk memaksimalkan performa komputasi. Sistem AI sekarang memaksa para engineer untuk sama seriusnya memikirkan lokalitas data, yaitu di mana informasi berada secara fisik relatif terhadap prosesor yang mencoba menggunakannya.
Sederhananya, jarak sekarang jauh lebih penting daripada dulu.
GPU Menjadi Begitu Cepat Sampai Bagian Sistem Lain Mulai Tertinggal
Salah satu hal menarik tentang infrastruktur AI adalah bahwa kemajuan di satu area cenderung memperlihatkan kelemahan di area lain.
Ketika GPU menjadi lebih cepat, bandwidth memori menjadi bottleneck. Hal itu mengarah ke HBM. Ketika keterbatasan kapasitas HBM menjadi semakin jelas, industri mulai memperkenalkan lapisan perantara seperti Storage Class Memory. Ketika penskalaan DRAM menjadi mahal dan sulit secara fisik, sistem mulai lebih banyak mengandalkan NAND sambil juga mengeksplorasi konsep seperti High Bandwidth Flash.
Dan ketika dataset AI terus berkembang ke kisaran petabyte dan exabyte, hard drive tetap diam-diam penting karena ekonomi untuk menyimpan informasi sebanyak itu tidak bisa berjalan dengan cara lain.
Setiap artikel dalam seri ini sebenarnya menunjuk ke kesimpulan yang sama dari sudut pandang yang berbeda.
Asumsi lama bahwa komputasi berada di sini sementara penyimpanan berada di sana mulai runtuh. Alasannya cukup sederhana: GPU sekarang dapat memproses data lebih cepat daripada arsitektur tradisional dapat mengirimkannya dengan nyaman.
Hal itu menciptakan situasi di mana sejumlah besar aktivitas sistem dihabiskan hanya untuk mengangkut informasi dari satu tempat ke tempat lain. Dalam praktiknya, beberapa lingkungan AI mulai terlihat kurang seperti masalah komputasi murni dan lebih seperti masalah logistik.
Industri Mulai Mengajukan Pertanyaan yang Berbeda
Untuk waktu yang lama, inovasi penyimpanan sebagian besar berfokus pada membuat perangkat penyimpanan menjadi lebih cepat. SSD yang lebih cepat, antarmuka yang lebih cepat, NAND yang lebih cepat, dan controller yang lebih cepat semuanya penting, dan masih penting hingga hari ini.
Namun workload AI mulai memperlihatkan masalah yang lebih dalam di bawah semua itu.
Pada titik tertentu, para engineer mulai menyadari bahwa masalahnya tidak selalu kecepatan perangkat penyimpanan itu sendiri. Masalahnya adalah perpindahan berulang dari data dalam jumlah sangat besar bolak-balik melintasi seluruh sistem.
Perbedaan yang halus itu penting, karena begitu masalahnya menjadi perpindahan data dan bukan sekadar kecepatan penyimpanan, solusinya juga mulai berubah.
Alih-alih terus bertanya bagaimana penyimpanan bisa dibuat lebih cepat, industri mulai bertanya seberapa jauh data harus bergerak sejak awal.
Pertanyaan itu sekarang memengaruhi hampir setiap bagian dari desain infrastruktur AI modern.
Memindahkan Komputasi Lebih Dekat ke Tempat Data Sudah Berada
Di sinilah arsitektur mulai bergeser.
Alih-alih memperlakukan penyimpanan sebagai lapisan yang sepenuhnya pasif dan hanya menunggu permintaan, sistem yang lebih baru mulai melakukan tugas-tugas tertentu lebih dekat ke data itu sendiri. Tidak harus berupa pemrosesan GPU skala penuh, tetapi operasi lokal yang mengurangi perpindahan yang tidak perlu di seluruh bagian sistem lainnya.
Beberapa sistem sekarang melakukan filtering, indexing, operasi pencarian, kompresi, persiapan retrieval, dan pengorganisasian data lebih dekat ke lapisan penyimpanan sebelum informasi tersebut pernah mencapai mesin komputasi utama.
Tujuannya bukan menghilangkan GPU atau menggantikan memori cepat. Tujuannya adalah mengurangi pemborosan.
Jika sistem dapat menghindari pengangkutan data yang tidak diperlukan dalam jumlah sangat besar melintasi infrastruktur, seluruh platform menjadi lebih efisien. Ini adalah salah satu alasan mengapa garis antara komputasi dan penyimpanan mulai kabur.
Penyimpanan tidak lagi berperilaku seperti tujuan yang sepenuhnya pasif di bagian bawah hierarki. Penyimpanan menjadi lebih terlibat dalam bagaimana data dipersiapkan, disusun, difilter, dan dikirimkan ke lapisan atas.
Jika Anda mengingat kembali artikel sebelumnya tentang High Bandwidth Flash, arah ini sangat masuk akal. Artikel itu menunjukkan bagaimana NAND sendiri didorong ke perilaku yang lebih mirip memori. Artikel ini memperluas gagasan yang sama satu langkah lebih jauh dengan menunjukkan bagaimana arsitektur di sekitarnya juga beradaptasi terhadap biaya perpindahan data.
Analogi Gudang Mulai Terlihat Berbeda
Analogi gudang yang kita gunakan sepanjang seri ini masih berlaku di sini, tetapi gudang itu sendiri mulai berevolusi karena pekerjaan di dalamnya telah berubah.
Dalam bagian-bagian sebelumnya, tata letaknya cukup mudah dipahami. HBM mewakili dock bongkar muat tempat pallet berikutnya sudah menunggu di samping para pekerja. DRAM bertindak sebagai lantai kerja aktif tempat penyortiran dan penanganan langsung berlangsung. Storage Class Memory menjadi area staging tepat di belakang dock, sementara NAND mewakili rak utama gudang yang berada lebih jauh ke belakang. Hard drive menangani penyimpanan bulk yang lebih dalam, tempat inventaris jangka panjang berada, karena kapasitas lebih penting daripada kecepatan akses langsung.
Model itu secara umum masih tetap masuk akal, tetapi sistem AI mulai memperlihatkan inefisiensi dalam seberapa banyak pergerakan yang terjadi di antara area-area tersebut.
Bayangkan sebuah gudang di mana para pekerja menghabiskan lebih banyak waktu mengendarai forklift bolak-balik melintasi bangunan daripada benar-benar memproses inventaris. Pada awalnya, manajemen merespons dengan membeli forklift yang lebih cepat, memperlebar lorong, dan memperbaiki dock bongkar muat. Peningkatan itu membantu untuk sementara, tetapi pada akhirnya operasi mencapai titik ketika transportasi itu sendiri menjadi masalah. Keterlambatan tidak lagi disebabkan oleh pekerja yang lambat atau peralatan yang kurang memadai. Keterlambatan datang dari banyaknya pergerakan yang diperlukan untuk menjaga workflow tetap berjalan.
Itulah yang semakin sering dihadapi oleh sistem AI besar.
Masalahnya bukan lagi hanya seberapa cepat data dapat diproses setelah mencapai GPU. Masalahnya adalah seberapa besar upaya infrastruktur yang dihabiskan untuk terus-menerus mengangkut data tersebut melintasi sistem sejak awal.
Jadi, alih-alih terus mengoptimalkan transportasi tanpa henti, tata letaknya mulai berubah. Workstation kecil mulai muncul lebih dekat ke rak itu sendiri. Tugas penyortiran tertentu terjadi secara lokal. Filtering terjadi secara lokal. Persiapan data mulai dilakukan lebih dekat ke tempat informasi sudah berada, sehingga sistem tidak perlu terlalu sering memindahkan material dalam jumlah sangat besar bolak-balik melintasi seluruh operasi.
Pergeseran itu pada dasarnya adalah apa yang mulai dilakukan infrastruktur AI pada tingkat arsitektur. Tujuannya bukan mengubah penyimpanan menjadi prosesor atau menghilangkan komputasi terpusat sepenuhnya. Tujuannya adalah mengurangi pergerakan yang tidak perlu, karena pada skala AI, bahkan inefisiensi kecil bisa menjadi sangat mahal ketika dikalikan dengan ribuan akselerator yang bekerja secara bersamaan.
Infrastruktur AI Menjadi Lebih Terdistribusi Karena Kebutuhan
Salah satu konsekuensi yang lebih menarik dari pergeseran ini adalah bahwa infrastruktur AI mulai menjadi jauh lebih terdistribusi daripada yang pernah dibutuhkan oleh lingkungan komputasi tradisional.
Arsitektur lama mengasumsikan bahwa sebagian besar pekerjaan penting akan terjadi di lokasi komputasi terpusat, sementara penyimpanan tetap sebagian besar pasif dan terpisah dari lapisan pemrosesan. Model itu bekerja cukup baik selama puluhan tahun karena jumlah data yang bergerak melalui sistem masih dapat dikelola dibandingkan dengan kecepatan prosesor yang mengonsumsinya.
AI mengubah skala persamaannya sepenuhnya.
Jumlah informasi yang diproses, dikunjungi kembali, disiapkan, di-cache, diindeks, dan diambil sekarang begitu besar sehingga perpindahan terpusat itu sendiri mulai menciptakan inefisiensi. Alih-alih komputasi sekadar menjangkau ke bawah menuju penyimpanan setiap kali membutuhkan sesuatu, sistem semakin berusaha menjaga data yang berguna tetap berada lebih dekat ke tempat data itu kemungkinan akan digunakan berikutnya.
Itulah sebagian alasan mengapa teknologi seperti database vektor, sistem inferensi terdistribusi, lapisan retrieval, caching lokal, dan pemrosesan dekat data mulai mendapat begitu banyak perhatian. Di permukaan, teknologi-teknologi ini mungkin terlihat seperti hal terpisah yang menyelesaikan masalah berbeda, tetapi di bawahnya semuanya merespons tekanan yang sama. Industri sedang mencoba mengurangi seberapa sering sejumlah besar informasi harus menempuh jarak jauh melintasi infrastruktur sebelum pekerjaan yang bermakna dapat dimulai.
Seperti yang mungkin Anda perhatikan sepanjang seri ini, hierarki memori itu sendiri secara bertahap menjadi kurang kaku dibandingkan dulu. Pemisahan bersih antara “komputasi di sini” dan “penyimpanan di sana” mulai melunak karena workload AI memberi keuntungan pada sistem yang menjaga data secara fisik lebih dekat ke tempat pemrosesan terjadi.
Tren itu kemungkinan akan terus berlanjut karena ekonomi AI skala besar semakin mengutamakan efisiensi dalam pergerakan, sama pentingnya dengan kemampuan komputasi mentah.
Hierarki Memori Mulai Saling Kabur
Salah satu tema yang lebih tenang di balik setiap bagian dalam seri ini adalah pengikisan bertahap terhadap batas lama antara memori, penyimpanan, dan komputasi.
Dalam artikel HBM, kita melihat bagaimana memori dipindahkan secara fisik lebih dekat ke prosesor itu sendiri, karena bahkan penempatan DRAM tradisional mulai memperkenalkan keterlambatan yang cukup besar untuk berarti pada skala AI. Dalam bagian Storage Class Memory, fokus bergeser ke pengurangan transisi tajam antara memori cepat dan penyimpanan persisten yang lebih lambat. High Bandwidth Flash mendorong NAND ke peran yang lebih aktif di dalam jalur data kerja, sementara artikel DRAM menunjukkan mengapa sekadar menaikkan skala memori tradisional tanpa batas menjadi sulit, baik secara ekonomi maupun fisik.
Sekarang artikel ini mendorong perkembangan yang sama satu langkah lebih jauh dengan menunjukkan bagaimana arsitektur itu sendiri beradaptasi terhadap biaya memindahkan data.
Yang membuat hal ini sangat menarik adalah bahwa tidak satu pun dari teknologi ini benar-benar menggantikan yang lain. Industri tidak meninggalkan NAND ketika HBM hadir. Industri tidak menggantikan DRAM hanya karena Storage Class Memory muncul. Hard drive juga tetap sangat relevan meskipun selama puluhan tahun ada prediksi bahwa penyimpanan solid-state akan menghilangkannya sepenuhnya.
Sebaliknya, sistem menjadi lebih berlapis, lebih terspesialisasi, dan lebih sadar terhadap di mana data berada secara fisik relatif terhadap sumber daya komputasi yang mencoba mengonsumsinya.
Perbedaan itu penting karena mengubah cara kita seharusnya memikirkan masa depan infrastruktur AI. Evolusi ini tidak terjadi karena satu teknologi terobosan tiba-tiba menyelesaikan semuanya. Evolusi ini terjadi karena workload itu sendiri memaksa industri mengatur ulang bagaimana setiap lapisan ikut berperan dalam memberi informasi ke sisi komputasi secara efisien.
Ketika Anda mundur selangkah dan melihat gambaran yang lebih besar, polanya menjadi jauh lebih mudah terlihat. Setiap pergeseran besar yang telah kita bahas sepanjang seri ini pada akhirnya mengarah ke tujuan yang sama: mengurangi berapa banyak waktu, energi, dan overhead infrastruktur yang dihabiskan hanya untuk memindahkan informasi dari satu tempat ke tempat lain.
Masa Depan Mungkin Lebih Bergantung pada Penempatan Data daripada Komputasi Mentah
Untuk waktu yang sangat lama, industri teknologi sebagian besar mengukur kemajuan melalui kemampuan komputasi mentah. Prosesor yang lebih cepat, akselerator yang lebih besar, lebih banyak core, dan paralelisme yang lebih tinggi diperlakukan sebagai indikator utama kemajuan karena, untuk sebagian besar workload tradisional, peningkatan performa komputasi umumnya meningkatkan sistem secara keseluruhan.
AI memaksa percakapan yang lebih bernuansa.
Begitu prosesor menjadi cukup cepat, tantangan yang lebih besar berhenti menjadi kemampuan menjalankan operasi dan mulai menjadi kemampuan menjaga prosesor tersebut tetap diberi data yang berguna secara cukup konsisten agar tidak terjadi waktu menganggur yang mahal. Perubahan halus itu sekarang memengaruhi hampir setiap keputusan arsitektur besar di dalam infrastruktur AI modern.
Bagian yang menarik adalah bahwa solusinya tidak lagi sekadar membuat perangkat penyimpanan yang lebih cepat atau pool memori yang lebih besar secara terpisah. Sebaliknya, industri semakin fokus pada di mana data berada di seluruh sistem, seberapa sering data bergerak, dan seberapa cerdas arsitektur dapat meminimalkan transportasi yang tidak perlu sebelum sumber daya komputasi ikut terlibat.
Itulah mengapa kedekatan menjadi tema yang terus berulang dalam setiap artikel seri ini. HBM memindahkan memori secara fisik lebih dekat ke GPU. Storage Class Memory mengurangi celah antara memori dan penyimpanan. High Bandwidth Flash mencoba membuat NAND berpartisipasi lebih aktif dalam hierarki memori. Sistem penyimpanan terdistribusi dan arsitektur pemrosesan dekat data sekarang mencoba mengurangi seberapa banyak pergerakan yang terjadi di dalam infrastruktur itu sendiri.
Semua perkembangan ini merespons kesadaran yang sama.
Pada skala AI, memindahkan data secara efisien menjadi hampir sama pentingnya dengan memproses data setelah data itu tiba.
Dan itu pada akhirnya bisa menjadi salah satu pergeseran arsitektur yang paling menentukan dalam seluruh era AI.
Seri Infrastruktur Memori AI
Artikel ini adalah bagian dari seri berkelanjutan kami tentang bagaimana infrastruktur AI membentuk ulang hubungan antara memori, penyimpanan, dan komputasi. Jika Anda baru masuk ke pembahasan ini dari sini, bagian-bagian sebelumnya memberikan dasar untuk memahami mengapa pergeseran ini terjadi.
Bagian Satu:
NAND tidak akan hilang, tapi server AI sekarang bergantung pada lebih dari sekadar flash
Bagian Dua:
Apa itu High Bandwidth Memory (HBM) dan mengapa AI bergantung padanya
Bagian Tiga:
Storage Class Memory dijelaskan: lapisan yang hilang antara DRAM dan NAND
Bagian Empat:
High Bandwidth Flash: bisakah NAND akhirnya bertindak seperti memori?
Bagian Lima:
Mengapa DRAM saja tidak lagi mampu mengimbangi AI
Bagian Enam:
Mengapa hard drive masih sangat penting untuk infrastruktur AI
Bagian Tujuh:
Mengapa AI memindahkan komputasi lebih dekat ke penyimpanan
Catatan Editorial: Artikel ini adalah bagian dari seri berkelanjutan tentang infrastruktur AI dan arsitektur memori yang diterbitkan oleh GetUSB.info. Artikel ini diteliti dan ditulis dengan dukungan editorial berbantuan AI untuk struktur dan keterbacaan, lalu ditinjau dan disempurnakan oleh tim editorial GetUSB untuk akurasi teknis, kesinambungan, dan kejelasan.
Tentang Penulis
Artikel ini dikembangkan di bawah arahan Matt LeBoff, kontributor lama GetUSB.info dengan pengalaman lebih dari dua dekade dalam teknologi USB, perilaku memori flash, dan sistem penyimpanan data. Perspektif yang disajikan di sini mencerminkan pengetahuan industri praktis dan analisis berkelanjutan tentang bagaimana sistem dunia nyata bekerja di bawah workload yang terus berkembang, termasuk infrastruktur AI.
